Фото с сайта Uza.uz
Фото с сайта Uza.uz
Окончательный вариант узбекского алфавита, основанного на латинице, не содержит буквенных сочетаний. Об этом сообщает «Газета.uz».
Вариант представила рабочая группа по совершенствованию узбекского алфавита, основанного на латинице, при Ташкентском государственном университете узбекского языка и литературы. Она окончательно отказалась от буквенных сочетаний «sh» и «ch» для обозначения кириллических «ш» и «ч», их заменят «ş» и «ç». Буквы «oʻ» («ӯ») и «gʻ» («ғ») будут представлены как «ó» и «ǵ».
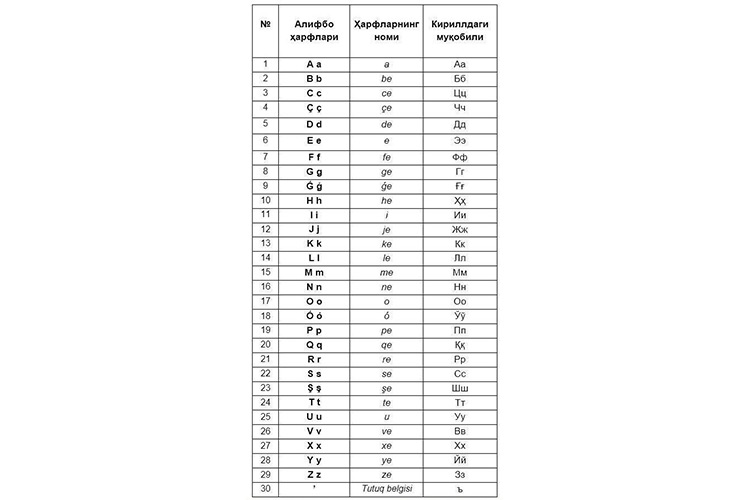
Обновленный алфавит состоит из 30 знаков, включая 29 букв и апостроф для обозначения твердого знака. Это фактически первоначальная версия, введенная в 1993 году (не считая буквы «ń»), сразу после того, как президент Ислам Каримов подписал закон «О введении узбекского алфавита, основанного на латинской графике». Тогда за основу был взят турецкий алфавит.
В 1995 году все буквы с диакритическими знаками были выведены из узбекского и заменены буквенными сочетаниями и буквами с перевернутым апострофом. Мотивом для обновления стало охлаждение отношений между Узбекистаном и Турцией, хотя официальной причиной было названо намерение упростить пользование англоязычной клавиатурой компьютеров. Этот алфавит неоднократно подвергался критике из-за недоработок, создающих неудобства при написании от руки, при наборе текстов на клавиатуре, а также при чтении. Языковеды полагают, что именно по этим причинам латиница не очень прижилась в Узбекистане.
Когда будет утвержден новый вариант алфавита, пока неизвестно.